Classic Systems Papers: Notes for CSE 221
UCSD recap, ep1
During my time at ucsd, I enjoyed their systems courses greatly. It’d be a shame to let those wonderful things I learnt fade away from my memory. So I compiled my notes into this article. I hope this can be helpful to future me and entertaining for others.
cse 221 is the entry course, introducing students to reading papers and the essential systems papers. The cast of papers is pretty stable over the years. Here is a syllabus of a cse 221 similar to the one I took, you can find links to the papers and extension reading there: CSE 221: Reading List and Schedule, Winter 2021.
THE System
The Structure of the “THE”-Multiprogramming System, 1968, by none other than Edsger W. Dijkstra.
The main take away is “central abstraction in a hierarchy”. The central abstraction is sequential process, and hierarchy is basically “layers”. The benefit of layers is that it’s easy to verify soundness and prove correctness for each individual layer, which is essential to handle complexity.
To Dijkstra, if a designer structures their system well, the possible test cases for the system at each level would be so few such that it’s easy to cover every possible case.
He then mentioned that “industrial software makers” has mixed feelings of this methodology: they agree that it’s the right thing to do, but doubt whether it’s applicable in the real world, away from the shelter of academia. Dijkstra’s stance is that the larger the project, the more essential the structuring. This stance is apparent in his other writings1.
The downside of layering is, of course, the potential loss of efficiently, due to either the overhead added by layering, or the lack of details hidden by lower layers. For example, the graphic subsystem in win32 was moved into the kernel in nt4, because there were too many boundary crossing.
And sometimes it’s hard to separate the system into layers at all, eg, due to circular dependency, etc. For example, in Linux, memory used by the scheduler is pinned and never page.
We also learned some interesting terminology used at the time; “harmonious cooperation” means no deadlock, and “deadly embrace” means deadlock.
Nucleus
The Nucleus of a Multiprogramming System, 1970.
Basically they want a “nucleus” (small kernal) that supports multiple simultaneous operating system implementations. So the user can have their os however they want. (Another example of “mechanism instead of policy”, sort of.) This school of thought would later reappear on exokernel and micro kernel.
The nucleus provides a scheduler (for process and i/o), communication (messages passing), and primitive for controlling processes (create, start, stop, remove).
In their design, the parent process is basically the os of their child processes, controlling allocation of resources for them: starting/stoping them, allocating memory and storage to them, etc.
However, the parent process doesn’t have full control over their children: it doesn’t control scheduling for it’s children. Nucleus handles scheduling; it divides computing time by round-robin scheduling among all active processes.
A more “complete” abstraction would be having nucleus schedule the top-level processes and let those processes schedule their children themselves. Perhaps it would be too inconvenient if you need to implement scheduler for every “os” you want to run.
HYDRA
HYDRA: The Kernel of a Multiprocessor Operating System, 1974.
The authros have several design goals for hydra: a) separation of mechanism and policy; b) reject strict hierarchy layering for access control, because they consider access control more of a mesh than layers; c) an emphasize on protection—not only comprehensive protection, but also flexible protection. They provide protection mechanism that can be used for not only for regular things like i/o, etc, but also arbitrary things that a higher-level program want to protect/control. It surely would be nice if unix has something similar to offer.
hydra structures protection around capabilities. Capability is basically the right to use some resource—a key to a door. Possessing the capability means you have the right of using whatever resource it references. For example, file descriptors in unix are capabilities: when you open a file, the kernel checks if you are allowed to read/write that file, and if the check passes, you get a file descriptor. Then you are free to read/write to that file as long as you hold the file descriptor; no need to go through access checks every time.
In genreal, in an access-controlled os, there are resources, like data or a device; execution domains, like “execute as this user” or “execute as this group”; and access control, controlling which domain can access which resource.
In hydra, there is procedure,
lns, and process. Procedure is a
executable program or a subroutine. lns
(local name space) is the execution domain. Conceptually it is a
collection of capabilities, it determines what you can and cannot do.
Each invocation of a procedure has a lns
attached to it. To explain it in unix
terms, when a user Alice runs a program ls, the capabilities
Alice has is the lns, and ls
is the procedure. Finally, a process is conceptually a (call) stack of
procedures with their accompanying lns.
Since each invocation of procedures have an accompanying lns, the callee’s lns could have more or different capabilities from its caller, so hydra can support right amplification.
Right amplification is when caller has more privilege/capabilities
than the caller. For example, in unix,
when a program uses a syscall, that syscall executed by the kernel has
far more privilege than the caller. For another example, when Alice runs
passwd to change her password, that program can modify the
password file which Alice has no access to, because passwd
has a euid (effective user id) with higher privilege.
Another concept often used in security is acl (access control list). It’s basically a table recording who has access to what. acl and capabilities each have their pros and cons. To use an acl, you need to know the user; with capabilities, anyone with the capability can have access, you don’t need to know the particular user. Capabilities is easier to check, and useful for distributed systems or very large systems, where storing information of all users/entities is not possible.
However, capabilities are unforgettable, ie, you can’t take it back. Maybe you can make them expire, but that’s more complexity. Capabilities can also be duplicated and given away, which has it’s own virtues and vices.
Since acl is easy to store and manage, and capability is easy to check, they are often used together. In unix, opening a file warrens a check in the acl, and the file descriptor returned to you is a capability.
It’s interesting to think of the access control systems used around us. Windows certainly has a more sophisticated acl than unix. What about Google Docs, eh? On top of the regular features, they also support “accessible through links”, “can comment but not edit”, etc.
TENEX
TENEX, a Paged Time Sharing System for the PDP-10, 1972.
tenex is the predecessor of multics, which in turn is the predecessor of unix. It runs on pdp-10, a machine very popular at the time: used by Harvard, mit, cmu, to name a few. pdp-10 was manufactured by bbn, a military contractor at the time. It’s micro-coded, meaning its instructions are programmable.
In bbn’s pager, each page is 512 words, the tlb is called “associative register”. Their virtual memory supports 256K words and copy-on-write. A process in tenex always have exactly one superior (parent) process and any number of inferior (child) processes. Processes communicate through a) sharing memory, b) direct control (parent to child only), and c) pseudo (software simulated) interrupts. Theses are also the only ways of ipc we have today in unix. Would be nice if we had message-passing built-in to the os. But maybe D-Bus is even better, since it can be portable.
tenex can run binary programs compiled for dec 10/50, the vendor os for the pdp-10. All the tenex syscalls “were implemented with the jsys instruction, reserving all old monitor [os/kernel] calls for their previous use”. They also implemented all of the dec 10/50 syscalls as a compatibility package. The first time a program calls a dec 10/50 syscall, that package is mapped “to a remote portion of the process address space, an area not usually available on a 10/50 system”.
tenex uses balanced set scheduling to
reduce pagefaults. A balanced set is a set of highest priority processes
whose total working set fits in memory. And the working set of a process
is the set of pages this process reference.
Guess what is an “executive command language interpreter”? They descried
it as “...which provides direct access to a large variety of small,
commonly used system functions, and access to and control over all other
subsystems and user programs”. It’s a shell!
Some other interesting facts: tenex supports at most 5 levels in file paths; the paper mentions file extensions; files in tenex are versioned, a new version is created every time you write to a file, old versions are automatically garbage collected by the system over time; tenex has five access rights: directory listing, read, write, execute, and append; tenex also has a debugger residing in the core memory alongside the kernel.
The file operations is the same as in unix, opening a file gives you a file descriptor, called jfn (job file number), and you can read or write the file. The effect of the write is seen immediately by readers (so I guess no caching or buffering). They even have “unthawed access”, meaning only one writer is allowed while multiple reader can read from the file at the same time. unix really cut a lot of corners, didn’t it?
Their conclusion section is also interesting…
One of the most valuable results of our work was the knowledge we gained of how to organize a hardware/software project of this size. Virtually all of the work on TENEX from initial inception to a usable system was done over a two year period. There were a total of six people principally involved in the design and implementation. An 18 month part-time study, hardware design and implementation culminated in a series of documents which describe in considerable detail each of the important modules of the system. These documents were carefully and closely followed during the actual coding of the system. The first state of coding was completed in 6 months; at this point the system was operating and capable of sustaining use by nonsystem users for work on their individual projects. The key design document, the JSYS Manual (extended machine code), was kept updated by a person who devoted full time to insuring its consistency and coherence; and in retrospect, it is out judgment that this contributed significantly to the overall integrity of the system.
We felt it was extremely important to optimize the size of the tasks and the number of people working on the project. We felt that too many people working on a particular task or too great an overlap of people on separate tasks would result in serious inefficiency. Therefore, tasks given to each person were as large as could reasonably be handled by that person, and insofar as possible, tasks were independent or related in ways that were well defined and documented. We believe that this procedure was a major factor in the demonstrated integrity of the system as well as in the speed with which it was implemented.
MULTICS
Protection and the Control of Information Sharing in Multics, 1974.
The almighty multics, running on the equally powerful Honeywell 6180. There are multiple papers on multic, and this one is about its protection system.
Their design principles are
- Permission rather than exclusion (ie, default is no permission)
- Check every access to every object2
- The design is not secret (ie, security not by obscurity)
- Principle of least privilege
- Easy to use and understand (human interface) is important to reduce human mistakes
multics has a concept of descriptor segments. The virtual memory is made of segments, and each segment has a descriptor, which contains access-control information: access right, protection domain, etc. This way, multics can access-control memory. The access check are done by hardware for performance. (Which means multics depends on the hardware and isn’t portable like unix).
multic uses an regular acl for file-access-control. When opening a file, the kernel checks for access rights, creates a segment descriptor, and maps the whole file into virtual memory as a segment. In the paper, the acl is described as the first level access-control, and the hardware-based access-control the second. Note that in multics, you can’t read a file as a stream: the whole file is mmaped into memory, essentially.
multics also has protected subsystems. It’s a collection of procedure and data that can only be used through designated entry points called “gates” (think of an api). To me, it’s like modules (public/private functions and variables) in programming languages, but in an os. All subsystems are put in a hierarchy: Every subsystem within a process gets a number, lower-numbered subsystems can use descriptors containing higher-numbered subsystems. And the protection is guaranteed by the hardware. They call it “rings of protection”.
Speaking of rings, x86 supports four ring levels, this is how kernel protects itself from userspace programs. Traditionally userspace is on ring 3 and kernel is on ring 0. Nowadays with virtual machines, the guest os is put on ring 1.
Protection
Protection, 1974.
This paper by Butler Lampson gave an overview of protection in systems, and introduces a couple useful concepts.
A protection domain is anything that has certain rights to do something and has some protection from other things, eg, kernel or userspace, a process, a user. A lot of words are used to describe it: protection context, environment, state, sphere, capability list, ring, domain. Then there are objects, things needs to be protected. Domains themselves can be objects.
The relationship between domains and objects form a matrix, the access matrix. Each relationship between a domain and an object can be a list of access attributes, like owner, control, call, read, write, etc.
When implementing the access matrix, the system might want to attach the list of accessible object of a domain to that domain. Each element of this list is essentially a capability.
Alternatively, the system can attach a list of domains that can access an object to that object. An object would have a procedure that takes a domain’s name as input and returns its access rights to this object. The domain’s name shouldn’t be forge-able. One idea is to use capability as the domain identifier: a domain would ask the supervisor (kernel) for an identifier (so it can’t be forged), and pass it to objects’ access-control procedure. An arbitrary procedure is often an overkill, and an access lock list is used instead.
Many system use a hybrid implementation in which a domain first access an object by access-key to obtain a capability, which is used for subsequent access. (Eg, opening a file and geting a file descriptor.)
UNIX
The UNIX Time-Sharing System, 1974.
The good ol’ unix! This paper describe the “modern” unix written in C, running on pdp-11.
Comparing to systems like tenex and multics, unix has a simpler design and does not require special hardware supports, since it has always been designed for rather limited machines, and for its creators’ own use only.
The paper spends major portions describing the file system, something we tend to take for granted from an operating system and view as swappable nowadays3. We are all too familiar with “everything as a file”. unix treats files as a linear sequence of bytes, but that’s not the only possible way. ibm filesystems has the notion of “records” like in a database4. And on multics, as we’ve seen, the whole file is mmaped to the memory5.
unix uses mounting to integrate multiple devices into a single namespace. On the other hand, ms dos uses filenames to represent devices.
This version of unix only has seven protections bits, one of which switches set-user-id, so there is no permission for “group”. set-user-id is essentially effective user id (euid).
The paper talked about the shell in detail, for example the |
< > ; & operators. Judging from the example, the
< and > are clearly intended to be
prefixes rather than operators (that was one of the mysteries for me
before reading this paper):
ls >temp1 pr -2 <temp1 >temp2 opr <temp2
Plan 9
Plan 9 From Bell Labs, 1995.
According to the paper, by the mid 1980’s, people have moved away from centralized, powerful timesharing systems (on mainframes and mini-computers) to small personal micro-computers. But a network of machines have difficulty serving as seamlessly as the old timesharing system. They want to build a system that feels like the old timesharing system, but is made of a bunch of micro-computers. Instead of having a single powerful computer that does everything, they will have individual micro-computers for each task: a computing (cpu) server, a file server, routers, terminals, etc.
The central idea is to expose every service as files. Each user can compose their own private namespace, mapping files, devices, and services (as files) into a single hierarchy. Finally, all communication are made through a single protocol, 9p. Compare that to what we have now, where the interface is essentially C abi plus web api, it certainly sounds nice. But on the other hand, using text stream as the sole interface for everything feels a bit shaky.
Their file server has an interesting storage called worm (write-once, read many), it’s basically a time machine. Everyday at 5 am, a snapshot of all the disks is taken and put into the worm storage. People can get back old versions of their files by simply reading the worm storage. Nowadays worm snapshot is often used to defend against ransom attacks.
Medusa
Medusa: An Experiment in Distributed Operating Systems Structure, 1980.
A distributed system made at cmu, to closely match and maximally exploit its hardware: the distributed-processor Cm* system (Computer Modules).
On a distributed processor hardware, they can place the kernel code in memory in three ways:
- Replicate the kernel on every node
- Kernel code on one node, other nodes’ processors execute code remotely
- Split the kernel onto multiple nodes
They chose the third approach: divide the kernel into utilities (kernel module) and distribute them among all the processors. When a running program needs to invoke a certain utility (basically some syscall provided by some kernel module), it migrates to the processor that has that utility. Different processors can have the same utility, so programs don’t have to fight for a single popular utility.
The design is primarily influenced by efficiency given their particular hardware, not structural purity, but some nice structure properties nonetheless arised. Boundaries between utilities are rigidly enforced, since each utility can only send messages to each other and can’t modify other’s memory. This improves security and robustness. For example, error in one utility won’t affect other utilities.
One problem that might occur when you split the kernel into modules is circular dependency and deadlocks. If the filesystem utility calls into the memory manager utility (eg, get a buffer), and the memory manager utility calls into the filesystem utility (eg, swap pages), you have a circular dependency. Mix in locks and you might get a deadlock.
To be deadlock-free, Medusa further divides each utility into service classes such that service classes don’t have circular dependencies between each other. It also makes sure each utility use separate and statistically allocated resources.
Programs written to run on Medusa are mostly concurrent in nature. Instead of conventional processes, program execution are carried out by task forces, which is a collection of activities. Each activity is like a thread but runs on different processors.
Activities access kernel objects (resources like memory page, pipe, file, etc) through descriptors. Each activity has a private descriptor list (pdl), and all activities in a task force share a shared descriptor list (sdl). There are also utility descriptor list (udl) for utility entry points (syscalls), and external descriptor list (xdl) referencing remote udl and pdl. Both udl and xdl are processor-specific.
The task force notion is useful for scheduling: Medusa schedules activities that are in the same task force to run in the same time. It’s often referred to as gang scheduling or coscheduling, where you schedule inter-communicating processes to run together, just like working sets in paging. In addition, Medusa does not schedule out an activity immediately when it starts waiting, and instead spin-waits for a short while (pause time), in the hope that the wait is short (shorter than context switch).
Utilities store information for an activity alongside the activity, instead of storing it on the utility’s processor. This way if an utilities fails, another utility can come in, read the information, and carry on the work. The utility seals the information stored with the activity, so user programs can’t muddle with it. Only other utilities can unseal and use that information. Implementation wise, unsealing means mapping the kernel object into the xdl of the processor running the utility; sealing it means removing it from the xdl.
Medusa’s kernel also provide some handy utilities like the exception reporter and a debugger/tracer. When an exception occurs, the kernel on the processor sends exception data to the reporter, which sends that information to other activities (buddy activity) to handle. And you can use the debugger/tracer to online-debug programs. Must be nice if the kernel drops you into a debugger when your program segfaults, no?6 I feel that Ken Thompson being too good a programmer negatively impacted the capability of computing devices we have today. If he wasn’t that good, perhaps they would add a kernel debugger in unix ;-)
Pilot
Pilot: An Operating System for a Personal Computer, 1980.
A system developed by Xerox parc on their personal work stations. Since it is intended for personal computing, they made some interesting design choices. The kernel doesn’t worry about fairness in allocating resources, and can take advices from userspace. For example, userspace programs can mark some process as high priority for scheduling7, or pin some pages in the memory so it’s never swapped out. (These are just examples, I don’t know for sure if you can do these things in Pilot.)
Pilot uses the same language, Mesa, for operating system and user programs. In result, the os and user programs are tightly coupled.
Pilot provides defense (against errors) but not absolute protection8. And protection is language-based, provided by (and only by) type-checking in Mesa.
Lastly, Pilot has integrated support for networks. It is designed to be used in a network (of Pilots). In fact, the first distributed email system is created on Pilot.
The device on which Pilot runs is also worth noting. ’Twas a powerful machine, with high-resolution bitmap display, keyboard, and a “pointing device”. Xerox parc basically invented personal computer, plus gui and mouse.
The filesystem is flat (no directory hierarchy), though higher level software are free to implement additional structure. Files are accessed through mapping its pages (blocks) into virtual memory. Files and volumes (devices) are named by a 64-bit unique id (uid), which means files created anywhere anytime can be uniquely identified across different machines (and thus across the network). They used a classic trick, unique serial number plus real-time clock, to guarantee uniqueness.
A file can be marked immutable. An immutable file can’t be modified ever again, and can be shared across machines without changing its uid. This is useful for, eg, sharing programs.
Monitor
Monitors: An Operating System Structuring Concept, 1974, by C. A. R. Hoare.
Experience with Processes and Monitors in Mesa, 1980.
Monitor is a synchronization concept. Think of it as a class that manages some resource and synchronizes automatically. In C, you would manually create a mutex and lock/unlock it; in Java, you just add some keyword in front of a variable and the runtime creates and manages the lock for you—that’s a monitor.
The Hoare paper introduced the concept and gave a bunch of examples. The Mesa paper describes how did they implement and use monitors in Mesa. If you recall, Mesa is the system and application language for Pilot.
Pilot uses monitors provided by Mesa to implement synchronization in the kernel, another example of the tight coupling of Pilot and Mesa.
I have some notes on the differences between Mesa’s monitors and Hoare’s monitors, but they aren’t very interesting. Basically Mesa folks needed to figure out a lot of details for using monitors for Pilot, like nested wait, creating monitor, handling exceptions in monitor, scheduling, class level vs instance level, etc.
Pilot didn’t use mutual monitors between devices. If two devices with orders of magnitude difference in processing speed shares a monitor, the fast device could be slowed down by waiting for the slower device to finish its critical section.
V Kernel
The Distributed V Kernel and its Performance for Diskless Workstations, 1983.
Back in the day, professors and their grad students work together to build an awesome and cutting-edge system, and journals invite them to write down their thoughts and experiences. Papers we’ve read up to this point are mostly describing the system the authors built, and sharing their experiences and lessons learned.
This paper is a bit different—it presents performance measurements and use it to argue a claim. You see, the conventional approach to build a distributed workstation is to use a small local disk for caching, and these systems usually use specialized protocols. This papar tries to build a distributed workstation without local disks (diskless) and only use generic message-based ipc. The authors argue that the overhead added by this two decisions are ok.
The paper introduced V message. It’s synchronous (request and
response), has a small message size (32
bytes), and has separate control data messages. Though they also have a
“control+data message” (ReplyWithSegment), presumably to
squeeze out some performance.
They used various measures to reduce the overhead. They put everything into the kernel, including the file server. They didn’t use tcp but used Ethernet frames directly. There is no separate ack message, instead ack is implied by a response.
The paper analyzed what network penalty consists of. When you send a message from one host to another, it goes from ram to the network interface, then it’s transferred on wire to the destination interface, then it’s copied into ram. Their argument is that message layer doesn’t add much overhead comparing to the base network penalty—copying between ram and network interface, and waiting in the interface before going onto the wire. They also argued that remote file access adds little overhead comparing to already-slow disk access.
Overall, their argument do have some cracks. For example, they argue that there is no need for specialized message protocol, but their protocol ends up specializing. They also argued that no streaming is needed, but large data packet are effectively streaming.
Sprite
The Sprite Network Operating System, 1988.
Sprite is another distributed system. It tries to use large memory cache to improve file access; and do it transparently, giving the user the illusion of a local system. It also has a very cool process migration feature. Sadly, process migration never caught up in the industry.
Several trends at the time influenced Sprite’s design. Distributed system was popular (at least in academia); memories are getting larger and larger; and more and more systems are featuring multiple processors.
To present the illusion of a local file system, Sprite uses prefix tables. Here, prefix means path prefix. When the userspace access a file, the kernel looks for a prefix of the path that’s in the prefix table. In the prefix table, the prefix can either point to the local filesystem or a remote filesystem. If it points to a remote filesystem, the kernel makes rpc calls to the remote host, which then access the local filesystem of that remote host.
Prefix table isn’t only useful for distributed system. In general, os that uses file paths usually cache the file paths it reads in a prefix table, because resolving a file path is very slow. When the os resolves a file path, it needs to read each directory in the path to find the next directory.
With cache, the biggest issue is consistency: if two clients get a file and stored it in their cache, and both write to their cache, you have a problem. Sprite’s solution is to allow only one writer at a time and track the current writer of every file. When a client needs to read a file, it finds the current writer and requests the file from it. This is sequential write-sharing.
If multiple clients needs to write the same file (concurrent write-sharing), Sprite just turns off caching. This is rare enough to not worth complicating the system. (And you probably need a substantially more complicated system to handle this.)
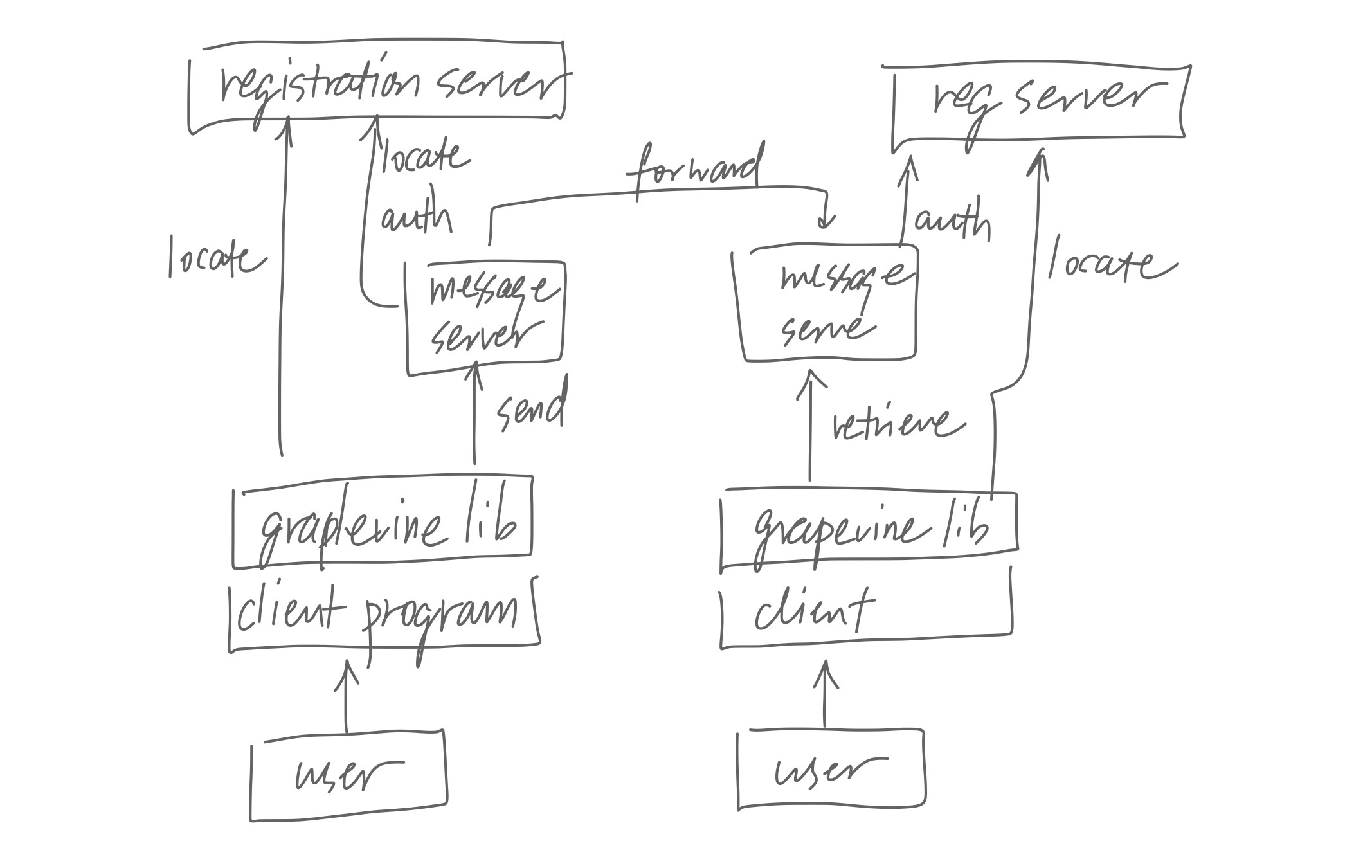
Grapevine
Experience with Grapevine: The Growth of a Distributed System, 1984.
A classic paper in distributed systems, even considered the multics of distributed systems by some. Grapevine is a distributed email delivery and management system; it provides message delivery, naming, authentication, resource location, access control—you name it.
The main takeaway is the experience they got from running Grapevine. To support scaling, the cost of any computation/operation should not grow as the size of the system grows. But on the other hand, sometimes you can afford to have complete information—maybe that information can never get too large, regardless of how large the system grows.
Grapevine generally tries to hide the distributed nature of the system, but that caused some problem. First of all, they can’t really hide everything: update in the sytem takes time to propagate, and sometimes users get duplicated messages, all of which are confusing for someone accustomed to the mail service on time-sharing systems.
More importantly, user sometimes needs to know more information of the underlying system to understand what’s going on: when stuff doesn’t work, people want to know why. For example, removing an inbox is an expensive operation and removing a lot of them in the same time could overload the system. System administrators needs to understand this, and to understand this they need to understand roughly how the system works under the hood.
The lesson is, complete transparency is usually not possible, and often not what you want anyway. When you design a system, it is important to decide what to make transparent and what not to.
Finally, the paper mentioned some considerations about managing the system. Maintaining a geographically dispersed system involves on-site operators and system experts. On-site operators carry out operations on-site, but has little to no understanding of the underlying system. System experts has deep understanding of the system, but are in short supply and are almost always remote from the servers they need to work on. Grapevine has remote monitoring and debugging features to help an expert to diagnose and repair a server remotely.
Global memory
Implementing Global Memory Management in a Workstation Cluster, 1995.
This paper is purely academic, but pretty cool nonetheless. They built a cluster that shares physical memory at a very low level, below vm, paging, file-mapping, etc. This allows the system to utilize the physical memory much better and allows more file-caching. More file caches is nice because cpu was becoming much faster than the disk.
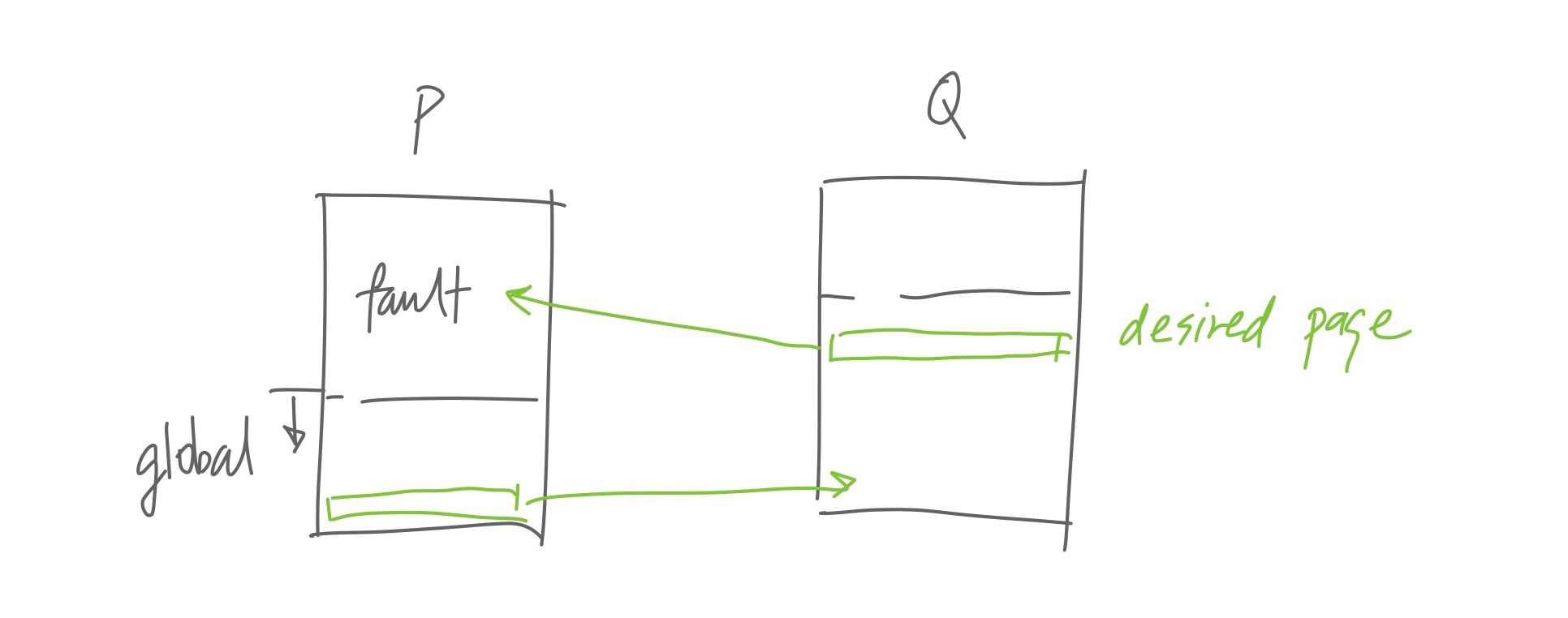
Each node in the cluster divides their memory into local memory and global memory. Local memory stores pages requested by local processes; global memory stores pages in behave of other nodes in the cluster.
When a fault occurs on a node P, one of four things could happen.
- If the requested page is in the global memory of another node Q, P uses a random page in its global memory to trade the desired page with Q. (See illustration 1.)
- If the requested page is in the global memory of another node Q, but P doesn’t have any page in its global memory, P use the least-recently used (lru) local page to trade with Q.
- If the requested page is on local disk, P reads it into its local memory, and evict the oldest page in the entire cluster to make room for the new page. If the oldest page is on P, evict that; if the oldest page is on a node Q, evict the page on Q, and send a page of P to Q. This page is either a random global page on P, or the lru local page of P if P has no global pages. (See illustration 2.)
- If the requested page is a local page of another node Q, duplicate that page into the local memory of P, and evict the oldest page in the entire cluster. Again, if the oldest page is on another node R, send one of P’s global pages or P’s lru page to trade with R.
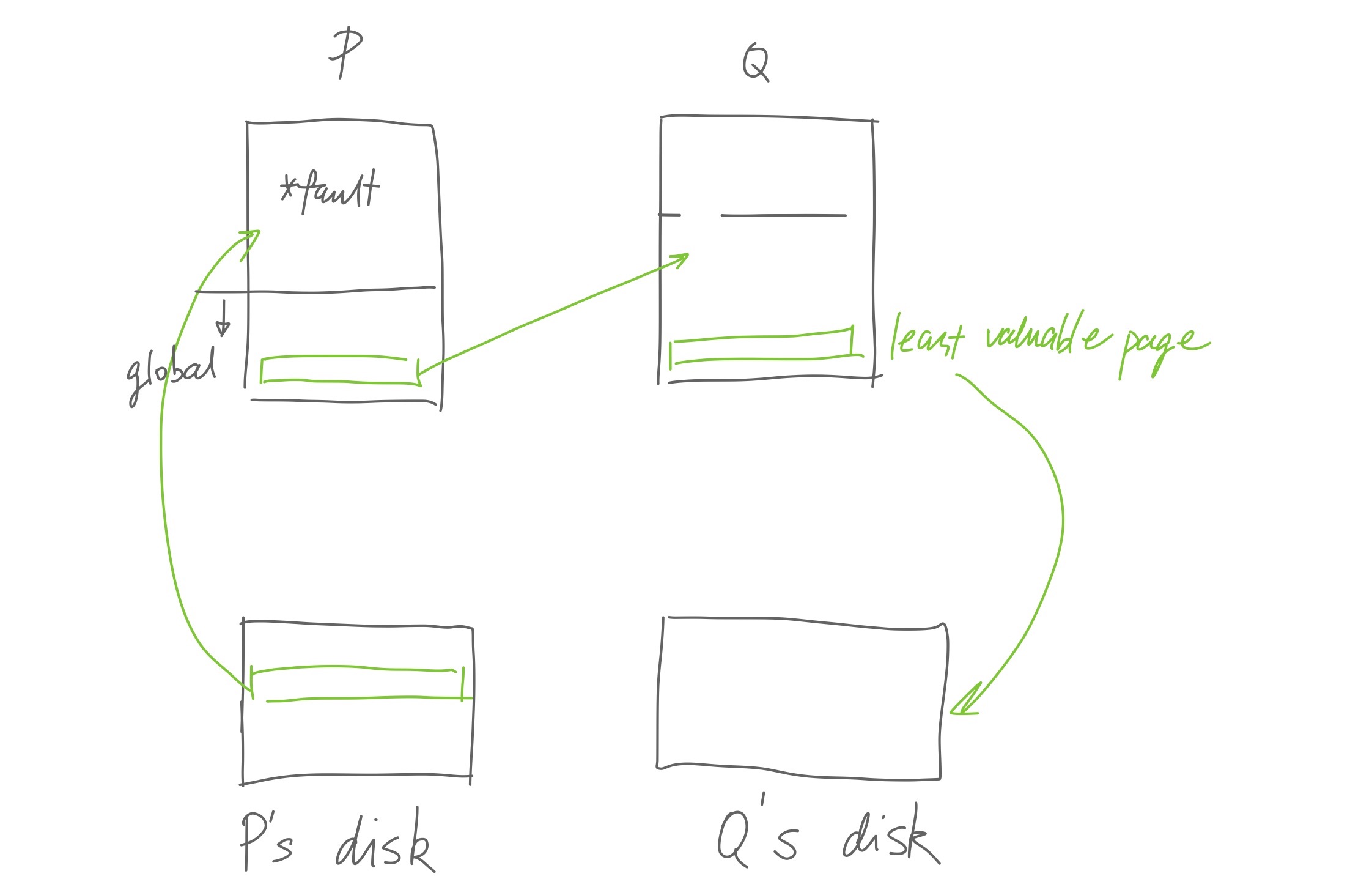
This whole dance can improve performance of memory-intensive tasks because fetching a page from remote memory is about two to ten times faster than disk access. However, local hit is over three magnitudes faster than fetching remote memory, so the algorithm has to be very careful not to evict the wrong page.
The description above omits a crucial problem: how does memory management code running on each node know which page is the oldest page in the entire cluster?
Consider the naive solution, where the system is managed by a single entity, a central controller. The controller keeps track of every single page’s age and tells each node which node to evict. Of course, this is impossible because that’s way too slow, the controller has to be running at a much faster speed than the other nodes and the communication speed between nodes must be very fast.
Instead, each node must make local independent decisions that combines to achieve a global goal (evict the oldest page). The difficulty is that local nodes usually don’t have complete, up-to-date information.
A beautiful approach to this kind of problem is probability-based algorithm. We don’t aim to make the optimal decision for every single case, but use probability to approximate the optimal outcome.
We divide time into epochs, in each epoch, the cluster expects to replace m oldest pages. (m is predicted from date from previous epochs.) At the beginning of each epoch, every node sends a summary of its pages and their age to an initiator node (central controller). The initiator node sorts all the pages by their age, and finds the set of m oldest pages in the cluster (call it W). Then, it assigns each node i a weight wi, where wi is
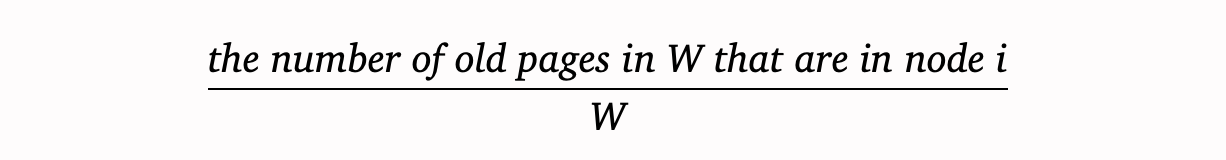
Basically, wi means “among the M oldest pages in the cluster, how many of them are in node i”.
The initiator node tells each node of every node’s weight, and when a node P encounters case 3 or 4 and wants to evict “the oldest page in the cluster”, it randomly picks a node by each node’s weight, and tells that node to evict its oldest page.
That takes care of finding which node to evict pages from, but tracking page age isn’t easy either. For one, in a mmaped file, memory access bypasses pagefault handler and goes straight to the tlb. More importantly, the os uses fifo second-chance page caching and hides many page request/eviction from their memory manager, because the memory manager runs at a lower level (presumably in pagefault handlers).
The authors resorted to hacking the tlb handler of the machine with PALcode (microcode). This would’ve been impossible on x86—it’s tlb is handled purely in hardware.
Probability-based algorithms sometimes feels outright magical—they seem to just bypass trade-offs. In reality, they usually just add a new dimension to the trade-off. We’ll see this again later in lottery scheduling.
μ-kernel
The Performance of μ-Kernel-Based Systems, 1997.
This paper is another measurement paper. It uses benchmarks to argue that a) micro kernel can deliver comparable performance, and b) the performance doesn’t depend on a particular hardware architecture.
The authors built a micro kernel L4, and ported Linux to run on it (called L⁴Linux). Then they ported L4 itself from Pentium to both Alpha and mips architecture—to show that L4 is architecture-independent. They also conducted some experiment to show L4’s extensibility and performance.
The paper considers micro kernels like Mach and Chrous to be first-generation, evolved out of earlier monolithic kernels. It considers later kernels like L4 and qnx to be second-generation, for that they are designed more rigorously from scratch, ie, more “pure”.
L4 allows user programs to control memory allocation like nucleus did: kernel manages top-level tasks’ memory, top-level tasks manages their children’s memory. And scheduling? Hard priorities with round-robin scheduling per priority, not unlike nucleus.
L⁴Linux only modifies the architecture-dependent part of Linux, meaning they didn’t have to modify Linux. The authors also restricted themselves to not make any Linux-specific change to L4, as a test for the design of L4. The result is not bad: in micro benchmarks, L⁴Linux is ×2.4 times slower than native Linux; in macro benchmarks, L⁴Linux is about 5–10% slower than native Linux. More over, L⁴Linux is much faster than running Linux on top of other micro kernels, like MkLinux (Linux + Mach 3.0).
The paper also mentions supporting tagged tlbs. Normal tlb needs to be flashed on context switch, which is a big reason why context switch is expensive. But if you tag each entry in the tlb with a tag to associate that entry with a specific process, you wouldn’t need to flush tlb anymore. The downside is that, tagged tlb needs some form of software-managed tlb, so not all architecture can support it. For example, x86 doesn’t support software-managed tlb.
The benefit of micro kernels is of course the extensibility. For example, when a page is swapped out, instead of writing to disk, we can swap to a remote machine, or encrypt the page and write to disk, or compress the page and write to page. A database program could bypass the filesystem and file cache, and control the layout of data on physical disk for optimization; it can control caching and keep pages in memory and not swapped out.
All of these are very nice perks, and the performance doesn’t seem too bad, then why micro kernels never caught on? Here’s our professor’s take: big companies can just hire kernel developers to modify Linux to their need9; smaller companies don’t have special requirements and can just use Linux. That leaves only the companies in the middle: have special requirements, but don’t want to modify Linux. (Professor’s take ends here.) However, extending micro kernel is still work, it might be easier than modifying Linux, but how much easier? Plus, if there are a lot of Linux kernel developers, perhaps modifying Linux is more easier afterall.
If we look at “we need a custom os” scenario today, Nintendo Switch and Playstation use modified bsd, Steam Deck is built on top of Linux. And I’m sure most data centers run some form of Linux.
Beyond monolithic and microkernel, there are many other kernel designs: hybrid, exokernel, even virtual machines. Hybrid kernels include Windows nt, NetWave, BeOS, etc. Hybrid kernel leaves some modules in the kernel, like ipc, driver, vm, scheduling, and put others in the userspace, like filesystem.
Exokernel
Exokernel: An Operating System Architecture for Application-Level Resource Management, 1997.
The idea is to go one step further than microkernels and turn the kernel into a library. Kernel exposes hardware resources, provide multiplexing and protection, but leaves management to the application. The motivation is that traditional kernel abstraction hides key information and obstructs application-specific optimizations.
This idea can be nicely applied to single-purpose applicants, when the whole purpose of a machine is to run a single application, eg, a database, a web server, or an embedded program. In this case, things that a traditional kernel provides like users, permissions, fairness, are all unnecessary overhead. (Unikernel explored exactly this use-case.)
Exokernel exports hardware resources and protection, and leaves management to the (untrusted) application. Applications can request for resources and handle events. Each application cooperatively share the limited resources by participating in a resource revocation protocol. Eg, the exokernel might tell an application to release some resources for others to use. Finally, the exokernel can forcibly retract resources held by uncooperative applications by the abort protocol.
Exokenel doesn’t provide many of the traditional abstractions, like vm or ipc, those are left for the application to implement.
The protection provided by an exokernel is inevitably weaker: an application error could corrupt on-disk data; and because the kernel and application runs in the same vm, application error could corrupt kernel memory!
The existence of abort protocol kind of breaks the “no management” principle—retracting resources from an application is management.
Finally, their benchmark isn’t very convincing: there are only micro benchmarks and no macro benchmark; they only benchmarked mechanism (context switch, exception handler, etc) and has no benchmark for application.
Xen
Xen and the Art of Virtualization, 2003.
Xen is a virtual machine monitor (vmm), also called hypervisor—the thing that sits between an os and the hardware. The goal of Xen is to be able to run hundreds of guest os’s in the same time.
Xen provides a virtual machine abstraction (paravirtualization) rather than a full virtual hardware (full virtualization). Paravirtualization has better performance and gives the vmm more control, but requires modification to the guest os. On the other hand, full virtualization vmm, for example VMWare, can work with unmodified guest os.
Nowadays there are a plethora of virtual machine solutions, like VMWare, Hyper-V, VirtualBox, kvm, Xen. On top of that, there are containers like lxc, docker, etc. The whole stack contains os, vmm/container engine, guest os, and guest app. These solutions all have different configurations: The vmm can sit on the host os or directly on the hardware; you can run one guest os per app, or run a single guest os for multiple apps; on the old ibm and vms systems, the vmm supports both a batch processing os and an interactive os.
Let’s look at how does Xen virtualize and how does it compare to VMWare.
Scheduling virtualization: Xen uses the Borrowed Virtual Time (bvt) algorithm. This algorithm allows a guest os to borrow future execution time to respond to latency-critical tasks.
Instructions virtualization: Boring instructions like add
can just pass-through to the hardware, but privileged instructions (like
memory access) needs intervention from the monitor.
In Xen, the guest os is modified so that it is aware of the vmm, and instead of doing privileged task by itself, the guest os delegates the work to the vmm by hypercalls. In VMWare, since they can’t modify the guest os, privileged instructions simply trap into vmm. If you remember, we talked about rings in the multics section. On x86, The cpu will trap if it’s asked to execute a privileged instruction when in a low ring level.
Memory virtualization: The guest os isn’t managing physical memory anymore, though we still call it physical memory. vmm has real access to the phyiscal memory, often called machine memory.
Then, how is the virtual memory address in the guest os translated into machine memory address?
In Xen, the guest os is aware of the virtualization. It’s page table can map directly from virtual address to machine address, and mmu can just read off of guest os’s page table. The vmm just need to verify writes to the page table to enforce protection.
In VMWare, however, the guest os is unaware of the vmm, and its page table maps from virtual address to physical address. Also, the guest os writes to its page table without bothering to notify anyone. vmm maintains a shadow page table that maps virtual address to actual machine address. It also uses dirty bits to make sure whenever the guest os writs to the page table, it is notified and can update its shadow page table accordingly. (I forgot exactly how.) And mmu reads off the shadow page table. (Presumably by trapping to vmm when the guest os tries to modify the cr3 register, and let vmm override cr3 to its shadow page table?)
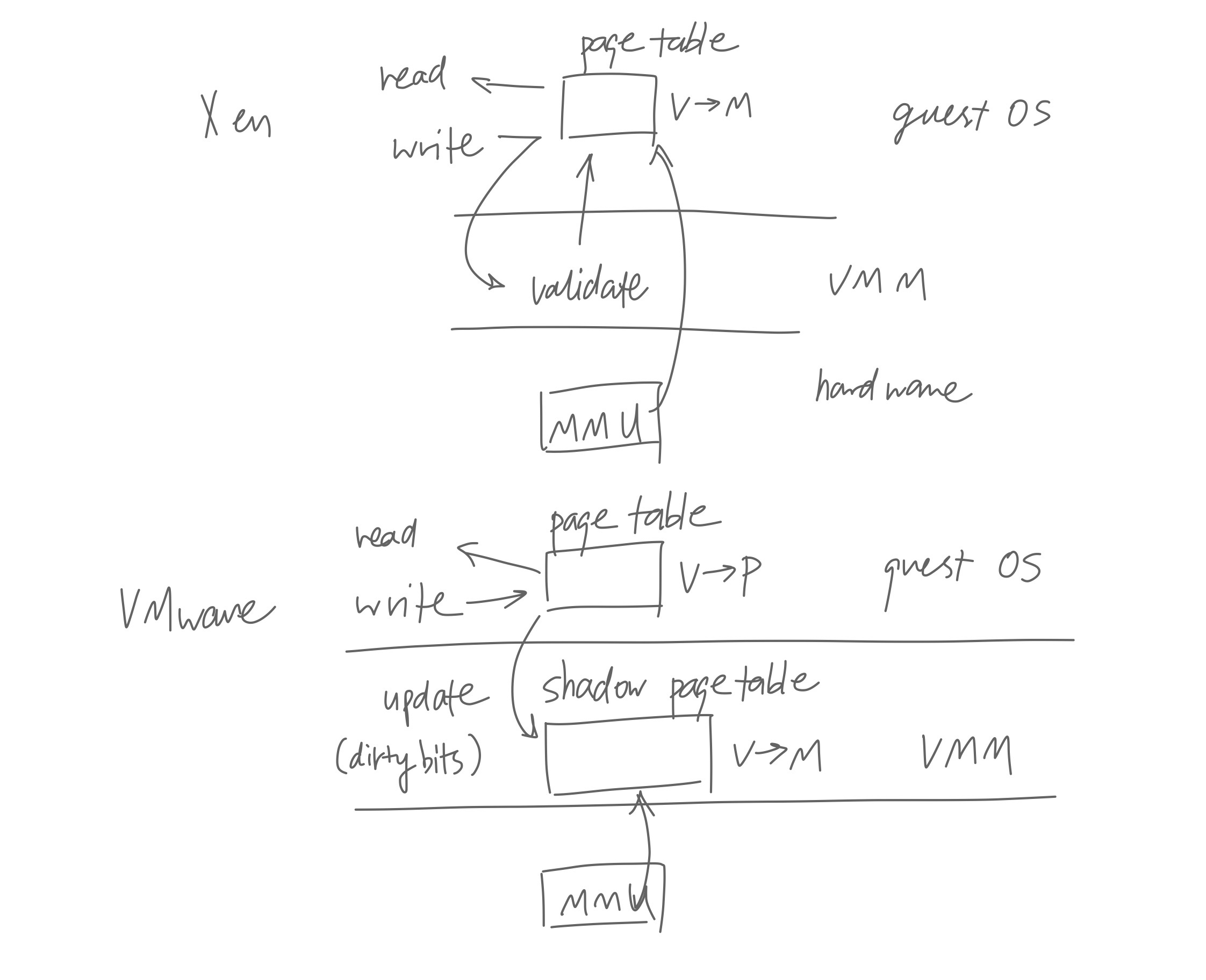
Note that VMWare needs all these complication only because x86’s memory management is completely hardware-based—the kernel can only point the mmu to the page table and has no other control over the mmu. Other “higher-end” architectures usually support software-managed and tagged tlb.
A clever trick that Xen uses is balloon driver. It’s a drive whose whole purpose is to take up memory. When the vmm wants to retract memory from the guest os, it enlarges the “balloon”, so the guest os relinquishes memory to the host.
VMS
Virtual Memory Management in VAX/VMS, 1982.
This paper mainly concerns of the implementation of the virtual memory for vms. vms has to run on a variety of low-end hardware with small memory and slow cpu; it also needs to support drastically different use-cases: real time, timeshared, and batch. These requirements all affected the design of vms.
vms’s virtual memory has three regions: program region, control region and system region. The highest two bits of an address indicates the region, after that are the regular stuff: 20 bits of virtual page number and 8 bits of byte offset. The system region (think of it as kernel stack) is shared by all processes; program and control region are process-specific.
The paper mentions a trick they used: they mark the first page in the
vm as no access, so that an uninitialized
pointer (pointing to 0x0) causes an exception. I think Linux
does the same.
vms uses a process-local page replacement policy. When a process requests for memory that needs to be paged in, kernel swaps out a page from this process’s resident set—the set of pages currently used by that process. This way a heavily paging process can only slow down itself.
When a page is removed from the resident set, it doesn’t go out of the memory immediately; instead, it’s appended to one of two lists. It goes to the free page list if it hasn’t been modified; otherwise it goes to the modified page list. When kernel needs a fresh page to swap data in, it takes a page from the head of the free list. When kernel decides to write pages back to paging file (swap file), it takes the page from the head of the modified list.
So a page is appended to the end of the list, and gradually moves to the head, until it’s consumed. But if the page is requested again by the process while still in the list, it is pulled out and put back into the the process’s resident set. This is basically second chance caching: we keep the page in the memory for a while before really discarding it, in case it is used again soon.
Because vms uses a relatively small 512 byte page size10, pages causes a lot of i/o, which is obviously not good. To reduce the number of disk operations, they try to read and write several pages at once (they call this clustering).
The paper also mentions some other nice features, like on-demand zeroed page, and copy-on-reference page. On-demand zeroed page are only allocated and zeroed when it’s actually referenced. Similarly, copy-on-reference pages are only copied when it’s actually referenced. I wonder why didn’t they make it copy-on-write though, they say it’s used for sharing executable files.
Quiz time: does kernel know about every memory access?
…The answer is no. Kernel only get to know about memory use when there’s a pagefault, which runs the pagefault handler provided by the kernel. If there’s no pagefault, memory access is handled silently by the mmu.
Mach
Machine-Independent Virtual Memory Management for Paged Uniprocessor and Multiprocessor Architectures, 1987.
Mach was a popular research os. In fact, our professor, Dr. Zhou, did her PhD on Mach’s virtual memory. Mach actually influenced both Windows and Mac: one of the prominent Mach researcher went to Microsoft and worked on Windows nt, and Mac osx was Mach plus bsd plus NextStep.
The main topic of this paper is machine-independent vm. The idea is to treat hardware information (machine-dependent, like tlb) as a cache of machine-independent information.
Mach’s page table is a sorted doubly linked list of virtual regions. Each virtual region stores some machine-independent info like address range, inheritance, protection, and some cache for the machine-dependent info. The machine-dependent part is a cache because it can be re-constructed from the machine-independent info. Also, since Mach uses doubly linked list, it can support sparse addresses (vms can’t).
Each virtual region maps a virtual address range to a range in a memory object. A memory object is an abstraction over some data; it can be a piece of memory, secondary storage, and even remote data, I think?
A memory object is associated with a pager, which handles pagefault and page-out requests. This pager is outside of the kernel and is customizable. And we can make it do interesting things like encrypting memory, remote memory, etc.
When performing a copy-on-write, Mac creates a shadow memory object which only contains pages that have been modified. Access to the unmodified page will be redirected to the original memory object. Since shadow memory objects themselves can be shadowed, sometimes, large chains of shadow objects will manifest. Mach has to garbage collect intermediate shadow objects when the chain gets long. Reading the paper, this seems to be tricky to implement and was quite an annoyance to the designers.
When a task inherits memory from its parent task, the parent can set the inheritance flag of any page to either shared (read-write), copy (copy-on-write), or none (no access). To me, this would be very helpful for sandboxing.
FFS
A Fast File System for UNIX, 1984.
This paper literally describes a faster file system they implemented for unix. It was widely adopted.
The author identifies a series of shortcomings of the default file system of unix:
The free list (a linked list of all free blocks) starts out ordered, but over time becomes random, so when the file system allocates blocks for files, those block are not physically continuous but rather scatter around.
The inodes are stored in one place, and the data (blocks) another. File operations (list directory, open, read, write) involve editing meta information interleaved with writing data, causing long seeks between the inodes and the blocks.
The default block size of 512 bytes is too small and creates indirection and fragmentation. Smaller block size also means it takes more disk transactions to transfer the same amount of data.
With all these combined, the default file system can only produce 2% of the full bandwidth.
ffs improves performance by creating locality as much as possible. It divides a disk partition into cylinder groups. Each cylinder group has its own copy of the superblock, its own inodes, and a free list implemented with a bitmap. This way inodes and data blocks are reasonably close to each other. Each cylinder has a fixed number of inodes.
ffs uses a smart allocation policy for allocating blocks for files and directories. It tries to place inodes of files in the same directory in the same cylinder group; it places new directories in a cylinder group that has more free inocdes and less existing directories; it tries to place all the data blocks of a file in the same cylinder group. Basically, anthing that improves locality.
ffs uses a larger block size since 512 bytes is too small. But larger block size wastes space—most unix systems are composed of many small files that would be smaller than a larger block size. ffs allows a block to be splitted into fragments. A block can be broken into 2, 4, or 8 fragments. At the end, the author claims that ffs with 4096-byte blocks and 512-byte fragments has about the same disk utilization as the old 512-byte block file system.
ffs requires some percent of free space to maintain it’s performance. When the disk is too full, it’s hard for ffs to keep the blocks of a file localized. ffs performs best when there are around 10% of free space. This applies to most modern filesystems too.
To maximally optimize the file system, ffs is parameterized so it can be tuned according to the physical property of the disk (number of blocks on a track, spin speed), processor speed (speed of interrupt and disk transfer), etc.
Here’s one example of how these information could improve performance. Two physically consecutive blocks on the disk can’t be read consecutively, because it takes some time for the processor to process the data after reading a block. ffs can calculate the number of blocks to skip according to the processor speed and spin speed, such that when the os finished reading one block, the next block of the file comes into position right under the disk head.
LFS
The Design and Implementation of a Log-Structured File System, 1991.
When this paper came out, it stirred quote some controversy on lfs vs extent-based ffs. Comparing to ffs, lfs has much faster writes, but it has slower read and needs garbage collection.
The main idea is this: since now machines have large rams, file cache should ensure read is fast; so the filesystem should optimize for write speed. To optimize write speed, we can buffer writes in the file cache and write them all at once sequentially.
This approach solves several shortcoming of ffs. In ffs, even though inodes are close to the data, they are still separate and requires seeking when writing. And the same goes for directories and files. The typical work load of the filesystem alternates between writing metadata and data, producing a lot of separate small writes. Further, most of the files are small, so most writes are really writing metadata. Writing metadata is much slower than writing files, because the filesystem has to do synchronous write for metadata, to ensure consistency in case of unexpected failure (power outage, etc).
On the other hand, lfs treats the whole disk as an append-only log. When writing a file, the filssytem just appends what it wants to write to the end of the log, followed by the new inodes pointing to the newly written blocks, followed by the new inode map pointing to the newly written inodes. The inode map is additionally copied in the memory for fast access.
To read, lfs looks into the inode map (always at the end of the log), finds the inodes, reads the inode to find the blocks, and pieces together the parts it wants to read.
When lfs has used the entire disk up, how does it keep appending new blocks? lfs divides the disk into segments, each consisting of a number of blocks. Some of the blocks are still being referenced (live blocks), some are free to be reused (free blocks). lfs will regularly perform garbage collection and create segments that only contains free blocks—during garbage collection, lfs copies all the live blocks in a segment to the end of the log, then this segment becomes a free segment. Finally, when lfs needs to write new logs, it writes them in free segments.
The challenge of garbage collection is to choose the best segment to clean. The authors first tried to clean least utilized segment first, ie, clean the segment with the least amount of live data. This didn’t go well, because segments don’t get cleaned until they cross the threshold, and a lot of segments lingers around the threshold, don’t get cleaned, and hold up a lot of space.
The authors found that it’s best to categorize segments into hot and cold segments. Hot segments are the ones that are actively updated, where blocks are actively marked free. Cleaning hot segments isn’t very valuable, because even if we don’t clean it, more and more of its blocks will become free by themselves. On the other hand, cold segments are valuable to clean, since it’s unlikely/slow to free up blocks by itself.
The authors also mentioned some crash recovery and checkpoint mechanism in the paper.
Soft update
Soft Updates: A Solution to the Metadata Update Problem in File Systems, 2000.
In lfs we mentioned that metadata edit requires synchronize writes. That’s because you want to ensure the data on disk (or any persistent storage) is always consistent. If the system writes only a partial of the data it wishes to write, then crashed, the disk should be in a consistent or at least recoverable state. For example, when adding a file to a directory, adding the new inode must happen before adding the file entry to the directory.
Folks has long sought to improve the performance of updating metadata, this paper lists several existing solutions.
- Nonvolatile ram (nvram)
- Use nvram to store metadata. Updating metadata is as fast as accessing ram, and it persists.
- Write-ahead logging
- Ie, journaling. The filesystem first log the operation it’s about to perform, and performs it. If a crash happens, the filesystem can recover using the log.
- Scheduler-enforced ordering
- Modify disk request scheduler to enforce synchronous edit of metadata. Meanwhile, the filesystem is free to edit metadata asynchronously (since the disk request scheduler will take care of it)
- Interbuffer dependencies
- Use write cache, and let the cache write-back code enforce metadata ordering.
Soft update is similar to “interbuffer dependencies”. It maintains a log of metadata updates, and tracks dependencies at a fine granularity (per field or pointer), and can move the order of operations around to avoid circular dependencies. Then it can group some updates together and make less writes.
Rio
The Rio File Cache: Surviving Operating System Crashes, 1996.
The main point of Rio (ram/Io) is to make memory survive crashes; then the os doesn’t have to consistently write the cache to persistent storage.
Power outages can be solved by power supply with battery and dumping memory to persistent storage when power outage occurs. Alternatively, we can just use persistent memory. Then, during reboot, the os goes through the dumped memory file to recover data (file cache). The authors call this “warm reboot”.
System crash is the main challenge, because kernel crash can corrupt
the memory. The authors argue that the reason why people consider
persistent storage to be reliable and memory to be unreliable is because
of their interface: writing to disk needs drivers and explicit
procedures, etc, while writing to memory only takes a mov
instruction.
Then, protecting the file cache is just a matter of write-protecting the memory. And there are a myriad of techniques for that already. For example, you can use the protection that virtual memory already provides. Just turn off the write-permission bits in the page table for file cache pages. However, some systems allow kernel to bypass virtual memory protection. The authors resorted to disabling processor’s ability to bypass tlb. This is of course architecture-dependent.
Another way is to install checks for every kernel memory access, but that’s a heavy penalty on the performance.
What’s more interesting is perhaps the effect of having a reliable memory on the filesystem. First, you can turn off reliable sync writes (this is the motivation for this paper in the first place). But also, since memory is now permanent, metadata updates must be ordered, so that a crash in the middle of an operation doesn’t create an inconsistent state.
Nowadays, persistent memory is getting larger and cheaper to the point that it seems possible to use it to improve io performance in datacenters. Problem is, every update has to be ordered, and you can’t control L1/2/3 cache. They can decide to write to memory at different orders than you intended.
Currently there are two approaches: treat the persistent memory as a super fast ssd, and slap a filesystem on it, the filesystem will take care of the dirty work. Others don’t want to pay for the overhead of a filesystem, and want to use it as a memory. To go this route, the programmer have to deal with the complications of consistency/ordering.
Scheduler activation
Scheduler Activations: Effective Kernel Support for the User-level Management of Parallelism, 1991.
Threading can be implemented in either kernel or userspace. However, both have their problems. If implemented in userspace, it has bad integration with kernel schedular—userspace thread scheduler has no way to know when a thread is going to run, and for how long. If implemented in kernel, thread management now requires a context-switch into kernel, which is very slow. Plus, like anthing else that goes into kernel, there won’t be much customizability.
The authors present a new abstraction as the solution—scheduler activation. The idea is to allow more cooperation between kernel and userspace. Kernel allocates processors, and notifies the userspace when it gives processors or takes processors away. The userspace decides what to run on the provided processors. Finally, the userspace can request or relinquish processors.
This way we get the best of both worlds: userspace thread scheduler has more information to make decisions, meanwhile userspace can do their own scheduling, requiring less context-switches.
When kernel notifies userspace of a change, it “activates” the userspace thread scheduler (that’s where the name “scheduler activation” comes from). A scheduler activation is like an empty kernel thread. When kernel wants to notify userspace of something, it creates a “scheduler activation”, assigns it a processor, and runs userspace scheduler in this “scheduler activation”. The userspace scheduler makes decisions by the information given in the scheduler activation by the kernel, then proceeds to run some thread on this scheduler activation.
The difference between a scheduler activation and normal kernel thread is that, when the kernel stops a scheduler activation, (maybe due to i/o), the kernel will create another scheduler activation to notify the userspace that the other scheduler activation has stopped; then the userspace scheduler can decide which thread to run on this scheduler activation. When the original scheduler activation is to be resumed (i/o completes), kernel blocks a running scheduler activation and creates a new scheduler activation, and let userspace scheduler decide which to run on this new scheduler activation.
For normal kernel threads, the kernel stops and resumes the thread without noticing userspace, and the kernel selects what to run.
Critical sections (where the executing program holds some locks) is a bit tricky in scheduler activation. When the thread is in critical section when it is blocked or preempted, performance might take a hit (no one else can run), or a deadlock might even appear. The solution is to let the thread run a little bit until it exits the critical section.
Scheduler activation is basically the n:m thread we’re taught in undergrad os classes. Evidentally it isn’t very widely used, maybe because the performance improvement isn’t worth the complexity.
Lottery scheduling
Lottery Scheduling: Flexible Proportional-Share Resource Management, 1994.
Lottery scheduling is another probability-based algorithm, it uses a simple algorithm to solve a otherwise difficult problem. I really like probability-based algorithms in general.11
Scheduling is hard. There are so many requirements to consider: fairness, overhead, starvation, priority, priority inversion12. However, lottery scheduling seemingly can have its cake and eat it too, solving all of the above simultaneously (with a catch, of course). Even better, lottery scheduling allows flexible distribution of resources, while normal priority-based scheduler only has corase control over processes: higher priority always wins13. It’s also general enough to apply to sharing other resources, like network bandwith or memory.
Here’s how it works. Suppose we have some processes and want to allocate some proportion of execution time to each. We create 100 tickets, and assign each process tickets based on their allocated proportion. Eg, if we want alloacte 30% of the execution time to process A, we assign it 30 tickets.
Then, we divide time into epochs. At the start of each epoch, we randomly draw a ticket out of the 100, and run the process that owns this ticket. Over a period of time, the total execution time of each process should match the assigned proportion.
Lottery scheduling is probabilistically fair. The shorter the epoch, and the longer the measured duration, the more accurate and fair is the scheduling. To ensure fairness, when a process wins lottery and executes in an epoch, only to be blocked by i/o midway, the scheduler would give it more ticket in the next epoch to compensate.
Lottery scheduling doesn’t have starvation. As long as a process has some ticket, the probability of it getting executed is not zero.
Lottery scheduling is very responsive to changes in configuration, because any change in the allocation proportion is immediately reflected in the next epoch. Some scheduler, like the fair-use scheduler mentioned earlier, might take longer to adjust priorities.
Lottery scheduling has very low overhead. It just need to generate a random number and find the process that owns it. It takes ~1000 instructions to run scheduling; it takes ~10 for generating a random number, and the rest for finding the process. The processes are stored in a linked list, ordered by the number of tickets held.
Lottery scheduling handles priority inversion by allowing processes to transfer tickets to other process. Traditional schedulers would use priority inheritance: the higher priority process elevates the lower priority process temporarily to execute and release the lock that the higher priority process needs. It’s the same principle, but instead of elevating priority, a process lends its tickets.
Of course, there’s always a catch. Lottery scheduling isn’t very good at immediate, strict control over resources. Eg, in a real-time system, a very high priority task has to be executed immediately when it comes up. Lottery scheduling can’t run it immediately (epoch), and it can’t guarantee to run it (randomized).
Also, the simple lottery scheduling can’t express response time (maybe something needs to run immediately but won’t take a lot of cpu time). We can add another parameter to represent response time, in addition to cpu time allocation. Not exactly sure how that works though.
Nowadays, lottery scheduling isn’t used so much for cpu scheduling, but widely used in networking.
Epilogue
That was the last classic paper. For the rest of the course, we went through some more recent literature like Android, gfs, MapReduce, Haystack. Those are no less filled with interesting ideas, but this article is already so long and I want to stop here.
Incidentally, as I’m writing this, there’s only two days left in 2023. Judging from the tags, I started this article in February 15 this year. Back then I didn’t know it’ll take a whole year to finish; during half way I thought I’ll never finish this. But look where we are now! Persistence really do get things done eventually.
I also started a programming project at around the same time, and that project (after much head-scratches and typing late at night) is also coming to fruition around this time. Looking back, I can’t believe that I actually pulled both of these off in 2023, oh my!